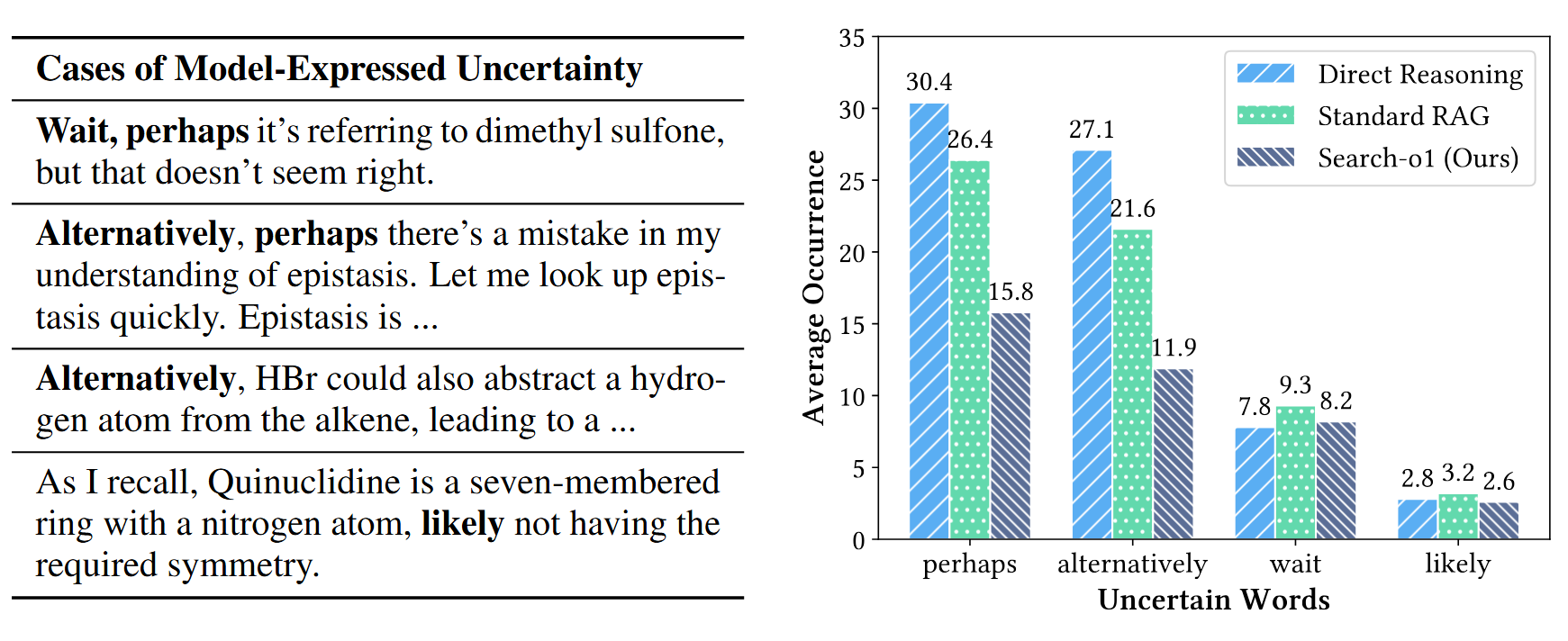
Analysis of reasoning uncertainty with QwQ-32B-Preview. Left: Examples of uncertain words identified during the reasoning process. Right: Average occurrence of high-frequency uncertain words per output in the GPQA diamond set.
In recent years, reasoning models such as OpenAI-o1 and Qwen-QwQ have demonstrated impressive step-by-step reasoning capabilities. However, these models often face challenges of knowledge insufficiency during long-chain reasoning, leading to uncertainties and potential errors in the reasoning process. To address this challenge, we propose a novel framework—Search-o1—designed to enhance the reliability and applicability of large reasoning models through autonomous knowledge retrieval.
Search-o1 integrates an agentic retrieval-augmented generation (RAG) mechanism and a Reason-in-Documents module to dynamically acquire and integrate external knowledge during the reasoning process. This approach allows reasoning models to autonomously retrieve relevant information when encountering uncertain knowledge points, thereby improving the coherence and accuracy of the reasoning chain. Extensive experiments on complex reasoning tasks in science, mathematics, and coding, as well as six open-domain QA benchmarks, demonstrate the strong performance of Search-o1. This framework enhances the trustworthiness and applicability of large reasoning models in complex reasoning tasks, paving the way for more reliable and versatile intelligent systems.
Large reasoning models achieve long-step, incremental reasoning through extensive reinforcement learning, making them suitable for complex domains such as science, mathematics, and coding. This "slow thinking" approach not only enhances the logical coherence and interpretability of reasoning but also introduces a significant issue: knowledge insufficiency. During the reasoning process, models may encounter uncertain knowledge points, causing error propagation throughout the reasoning chain and affecting the quality of the final answers.
Preliminary experiments reveal that reasoning models similar to OpenAI-o1 encounter over 30 instances of uncertain terms, such as "perhaps" and "possibly," on average during each reasoning process when handling complex problems. This not only increases the complexity of reasoning but also makes manual verification of the reasoning process more challenging. Therefore, automating the supplementation of necessary knowledge during reasoning has become crucial for enhancing the trustworthiness of large reasoning models.
Analysis of reasoning uncertainty with QwQ-32B-Preview. Left: Examples of uncertain words identified during the reasoning process. Right: Average occurrence of high-frequency uncertain words per output in the GPQA diamond set.
To overcome the aforementioned challenges, we propose the Search-o1 framework. This framework integrates autonomous retrieval-augmented generation (Agentic Retrieval-Augmented Generation) mechanisms and a Reason-in-Documents module to dynamically acquire and integrate external knowledge during the reasoning process.
The Search-o1 framework addresses knowledge insufficiency in large reasoning models (LRMs) by seamlessly integrating external knowledge retrieval into their reasoning process while maintaining chain-of-thought coherence. As illustrated in Figure, we present a comparative analysis of three approaches: vanilla reasoning, agentic retrieval-augmented generation (RAG), and our proposed Search-o1 framework.
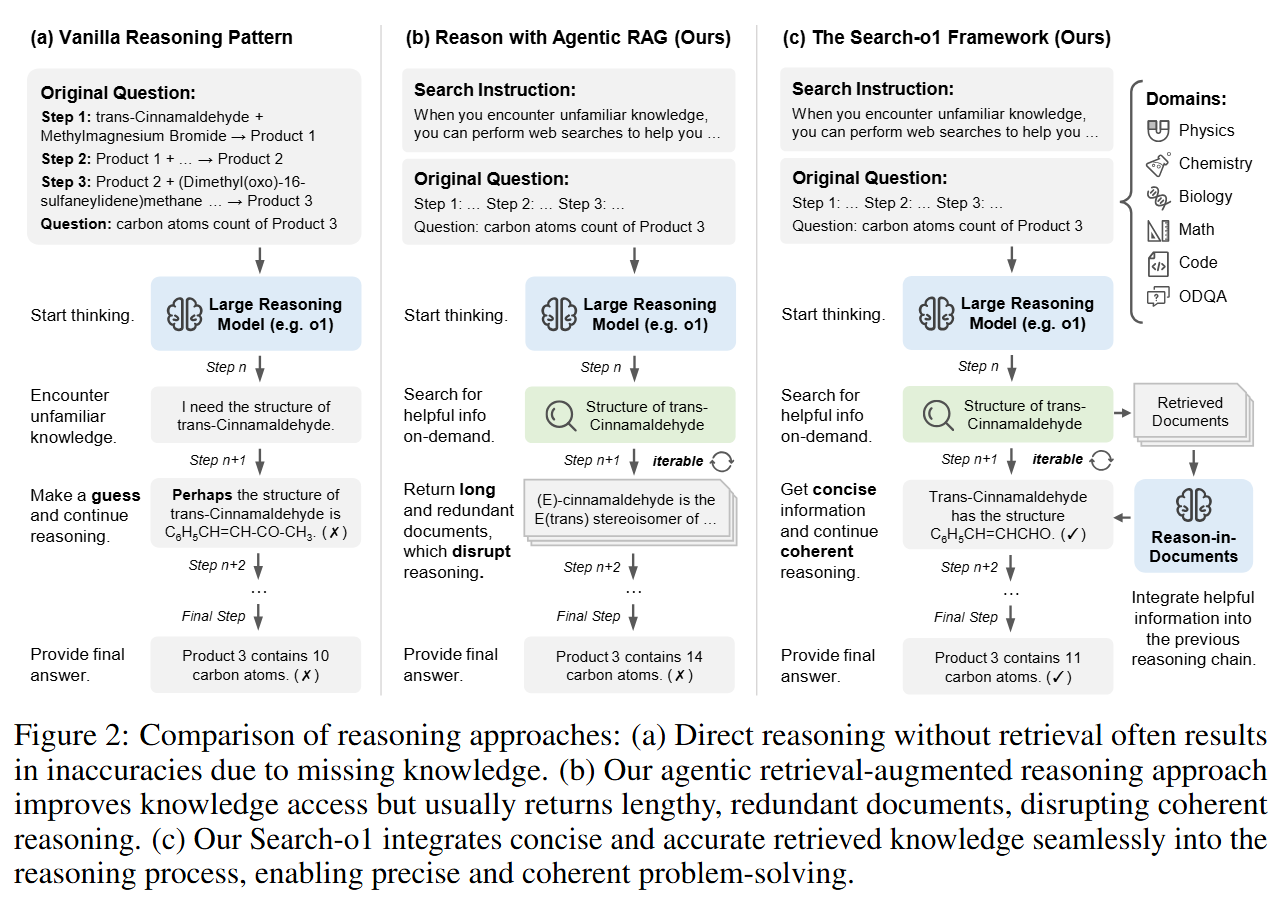
Comparison of reasoning approaches, including (a) vanilla reasoning pattern, (b) our reasoning approach with agentic RAG, and (c) our Search-o1 framework that enhances large reasoning models with agentic RAG and the reason-in-documents module.
For each question, the Search-o1 inference starts by combining the task instructions with the specific question. As the reasoning model generates the reasoning chain, it may create search queries marked with special symbols. When a search query is detected, it triggers the retrieval of relevant external documents. These documents are then processed by the Reason-in-Documents module, which extracts and refines the necessary information. The refined knowledge is integrated back into the reasoning chain, ensuring that the model incorporates essential external information while maintaining a coherent and logical flow, ultimately leading to a comprehensive reasoning process and the final answer.
To handle multiple questions efficiently, the Search-o1 framework uses a batch inference mechanism that processes all questions simultaneously. It starts by initializing reasoning sequences for each question and then generates tokens in parallel for all sequences. When a search query is identified in any sequence, the framework retrieves the necessary documents in batches. The Reason-in-Documents module then refines these documents collectively, and the relevant information is inserted back into each respective reasoning chain. Completed reasoning sequences are moved to a finished set, while ongoing ones continue to be processed. This parallel approach significantly improves the system's efficiency and ability to manage multiple inputs at the same time.

We evaluated Search-o1 on challenging reasoning tasks, including GPQA, mathematics and coding, and open-domain QA tasks, including single-hop and multi-hop QA tasks. The results showcase Search-o1's exceptional performance, confirming that the search mechanism effectively fulfills the model's knowledge requirements during reasoning.
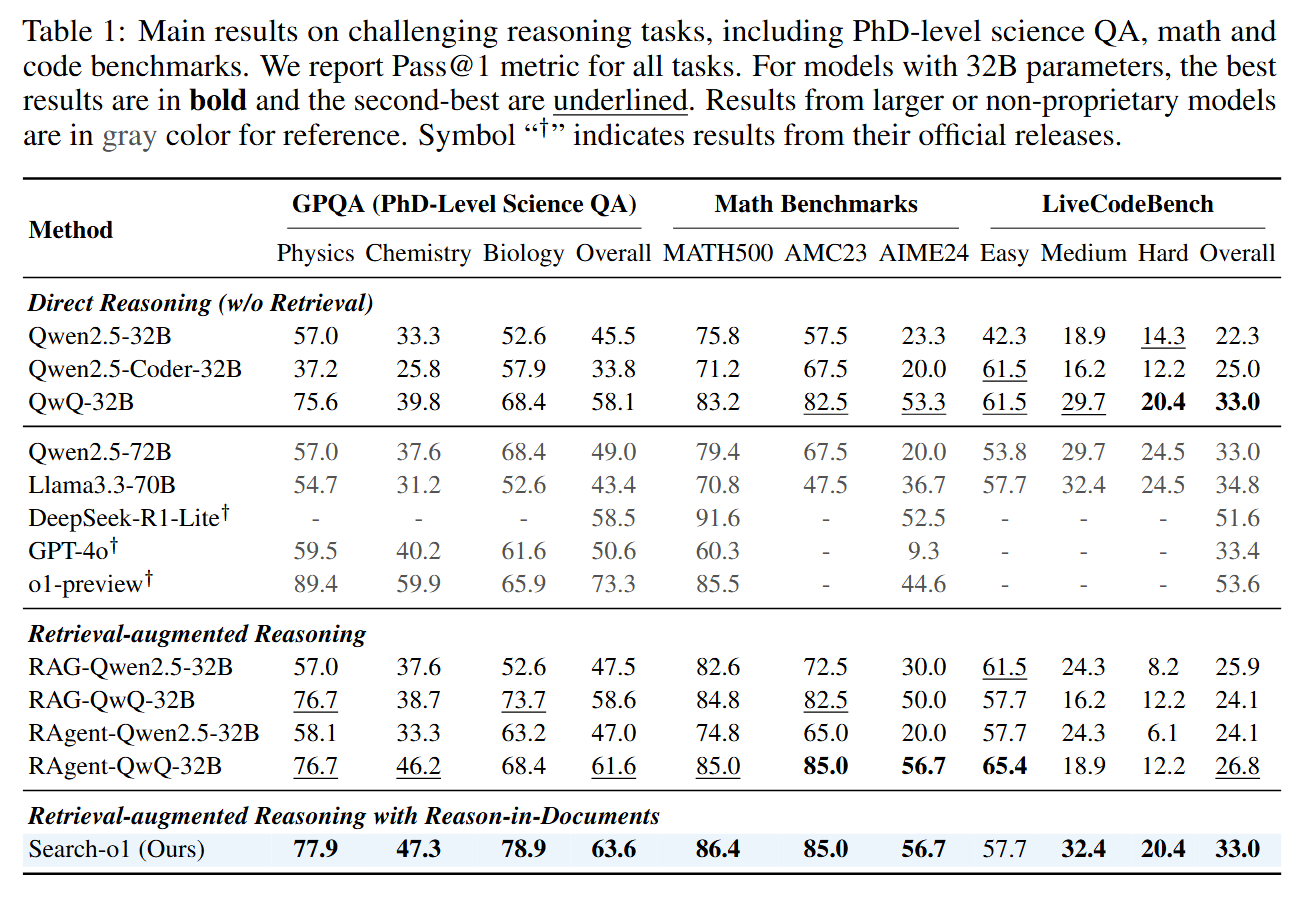
Main results on challenging reasoning tasks, including PhD-level science QA, math and code benchmarks.
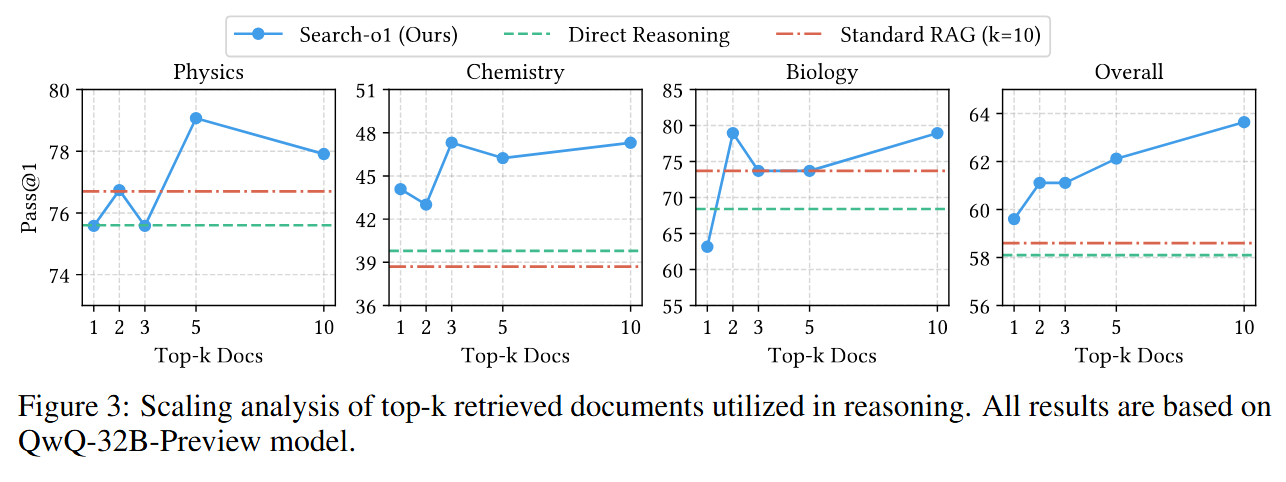
Scaling analysis of top-k retrieved documents utilized in reasoning. All results are based on QwQ-32B-Preview model.
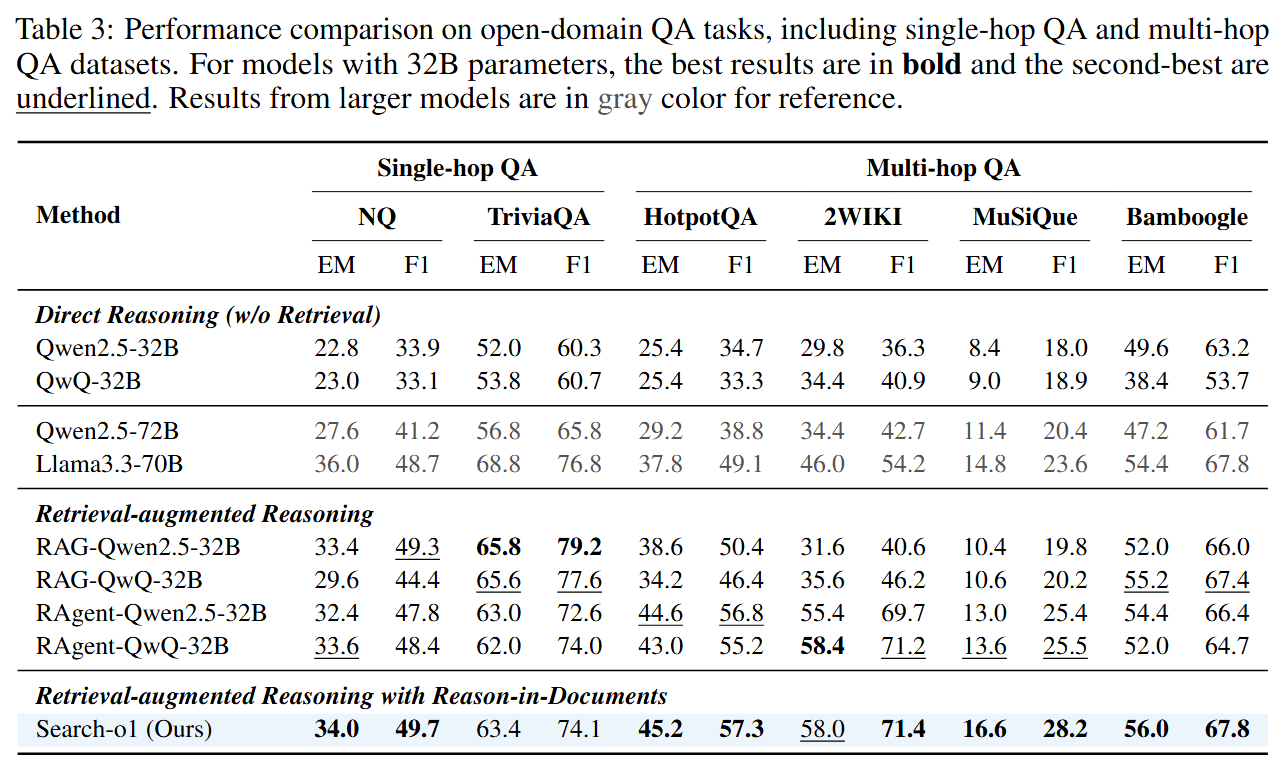
Performance comparison on open-domain QA tasks, including single-hop QA and multi-hop QA datasets.

Case study #1 of Search-o1 on GPQA dataset, with the backbone model QwQ-32B-Preview.

Case study #2 of Search-o1 on AMC2023 dataset, with the backbone model QwQ-32B-Preview.

Case study #3 of Search-o1 on HotpotQA dataset, with the backbone model QwQ-32B-Preview.
@article{DBLP:journals/corr/abs-2501-05366,
author = {Xiaoxi Li and
Guanting Dong and
Jiajie Jin and
Yuyao Zhang and
Yujia Zhou and
Yutao Zhu and
Peitian Zhang and
Zhicheng Dou},
title = {Search-o1: Agentic Search-Enhanced Large Reasoning Models},
journal = {CoRR},
volume = {abs/2501.05366},
year = {2025},
url = {https://doi.org/10.48550/arXiv.2501.05366},
doi = {10.48550/ARXIV.2501.05366},
eprinttype = {arXiv},
eprint = {2501.05366},
timestamp = {Wed, 19 Feb 2025 21:19:08 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2501-05366.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}